Cómo configurar un entorno de desarrollo de IA local en cualquier equipo
Aprende a configurar un entorno de desarrollo de IA local completo en cualquier equipo usando Ollama. Esta guía detallada cubre los requisitos de hardware (GPU, Apple Silicon, CPU), la gestión de modelos, la integración con IDE (VS Code, JetBrains) y benchmarks de rendimiento para ejecutar modelos de lenguaje grande (LLM) localmente con cero costes de API y privacidad total de los datos.
Por qué importa el desarrollo local de IA
Ejecutar modelos de IA de forma local ha pasado de ser un hobby de nicho a una necesidad profesional. Las razones son contundentes: cero costes de API durante el desarrollo y las pruebas, privacidad total de los datos para proyectos sensibles, funcionamiento sin conexión que te libera de la dependencia de internet, y la capacidad de experimentar libremente sin preocuparte por límites de uso o tarifas. Quizás lo más importante es que el desarrollo local te proporciona una comprensión profunda de cómo funcionan realmente los modelos de IA: sus características de latencia, modos de fallo y límites de rendimiento, conocimientos esenciales para crear aplicaciones robustas basadas en IA.
Esta guía te llevará paso a paso por la configuración de un entorno de desarrollo de IA local completo en cualquier equipo, desde una estación de trabajo de gama alta con varias tarjetas gráficas hasta un MacBook Pro o un portátil modesto con solo gráficos integrados. Cubriremos Ollama para la gestión de modelos, la integración con IDE para un desarrollo fluido, y los compromisos entre GPU y CPU que determinan qué puedes ejecutar realmente.
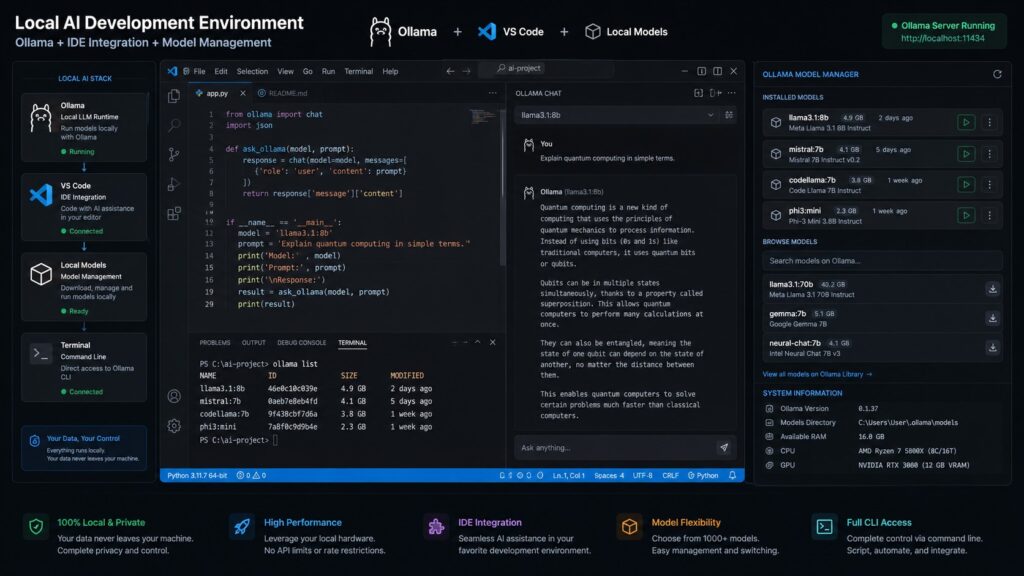
Configuración de un entorno de desarrollo de IA local con integración en IDE
Elegir tu estrategia de hardware
Antes de instalar nada, evalúa con honestidad las capacidades de tu hardware. Esto determinará qué modelos podrás ejecutar y con qué fluidez.
Configuración basada en GPU (recomendada)
Las tarjetas gráficas dedicadas ofrecen, con diferencia, la mejor experiencia de IA local. La métrica clave es la memoria VRAM (memoria de vídeo), que determina el tamaño de los modelos:
- 8 GB de VRAM (RTX 4060, RTX 3070) — Ejecuta modelos de 7-8 mil millones de parámetros cómodamente con cuantización de 4 bits. Este es el mínimo para una buena experiencia de desarrollo local.
- 12 GB de VRAM (RTX 4070) — Ejecuta modelos de 7-8B con precisión completa o modelos de 13B con cuantización. Bueno para la mayoría de las tareas de desarrollo.
- 16 GB de VRAM (RTX 4080, RTX 4070 Ti Super) — Ejecuta modelos de 13B cómodamente y modelos de 34B con cuantización agresiva. El punto óptimo para el desarrollo local serio de IA.
- 24 GB de VRAM (RTX 4090, RTX 3090) — Ejecuta modelos de 34B cómodamente y modelos de 70B con cuantización de 4 bits. Capacidad de IA local de nivel profesional.
Configuración con Apple Silicon
Los chips de la serie M de Apple con memoria unificada son sorprendentemente capaces para la IA local. La arquitectura de memoria unificada significa que la GPU puede acceder a toda la RAM del sistema, lo que da a los equipos con Apple Silicon una ventaja efectiva de VRAM:
- M1/M2 con 16 GB — Equivalente a una GPU de 12 GB. Ejecuta bien modelos de 7B.
- M2/M3 Pro con 18-36 GB — Equivalente a una GPU de 16-24 GB. Ejecuta bien modelos de 13-34B.
- M2/M3/M4 Max con 64-128 GB — Equivalente a una GPU de 48-96 GB. Puede ejecutar modelos de 70B con cuantización. Estos equipos son, sin duda, las mejores plataformas de un solo dispositivo para el desarrollo local de IA gracias a su enorme VRAM efectiva.
- M2/M4 Ultra con 128-192 GB — Puede ejecutar modelos muy grandes que requerirían configuraciones multi-GPU en otras plataformas.
Configuración solo con CPU
Ejecutar modelos solo con CPU es posible, pero significativamente más lento. Espera entre 2-10 tokens por segundo en CPU modernas para modelos de 7B, en comparación con 30-100+ tokens por segundo en GPU. La inferencia por CPU es viable para desarrollo y pruebas, pero poco práctica para chats interactivos o iteración rápida. Si estás en un equipo solo con CPU, considera usar modelos más pequeños (3B parámetros o menos) y aceptar tiempos de respuesta más largos.
Instalación de Ollama: El gestor universal de modelos
Ollama se ha convertido en el estándar de facto para ejecutar modelos de IA localmente. Gestiona la descarga de modelos, la cuantización, la aceleración por GPU y proporciona una API sencilla compatible con el formato de OpenAI. Piensa en ello como el Docker para modelos de IA: abstrae la complejidad de la gestión de modelos para que puedas centrarte en el desarrollo.
Instalación
macOS y Linux:
# macOS: Descargar desde ollama.com o usar Homebrew
brew install ollama
# Linux: Instalar con el script oficial
curl -fsSL https://ollama.com/install.sh | shWindows:
Descarga el instalador desde ollama.com y ejecútalo. Ollama detecta automáticamente tu GPU y configura la aceleración.
Verificación de la instalación
# Iniciar el servicio de Ollama
ollama serve
# En otra terminal, verificar que está funcionando
ollama --version
# Descargar y ejecutar tu primer modelo
ollama pull llama3.1:8b
ollama run llama3.1:8bCuando ejecutas un modelo por primera vez, Ollama lo descarga automáticamente. El tamaño de la descarga depende del modelo: un modelo cuantizado de 8B ocupa unos 4,7 GB, mientras que un modelo de 70B ocupa unos 40 GB. Una vez descargado, los modelos se inician al instante.
Prueba de la API
Ollama expone una API local en el puerto 11434 que es compatible con el formato de completado de chat de OpenAI:
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.1:8b",
"messages": [
{"role": "user", "content": "Escribe un haiku sobre programación."}
]
}'Gestión de modelos: Qué instalar
Con Ollama instalado, debes elegir qué modelos mantener localmente. Aquí tienes una selección organizada por caso de uso:
Uso general (empieza aquí)
# Mejor modelo para la mayoría de las tareas
ollama pull llama3.1:8b
# Mayor capacidad de razonamiento, requiere 16 GB+ de VRAM
ollama pull llama3.1:70b
# Rápido y eficiente, ideal para tareas simples
ollama pull mistral:7bAsistencia para programación
# Diseñado específicamente para generación y depuración de código
ollama pull codestral:22b
# Excelente modelo de código con soporte para múltiples lenguajes
ollama pull qwen2.5-coder:7b
# Modelo de código de DeepSeek, calidad de primer nivel
ollama pull deepseek-coder-v2:16bRápidos y ligeros
# Pequeño pero sorprendentemente capaz
ollama pull phi3:mini
# Ideal para tareas de clasificación y extracción
ollama pull gemma2:2bModelos de embeddings (esenciales para RAG)
# Modelo estándar de embeddings para búsqueda vectorial
ollama pull nomic-embed-text
# Modelo de embeddings multilingüe
ollama pull mxbai-embed-largeIntegración con IDE para desarrollo con IA
Ejecutar modelos en una terminal es útil, pero los verdaderos beneficios de productividad llegan cuando integras la IA directamente en tu flujo de trabajo de desarrollo. Estas son las mejores opciones para cada IDE principal:
Integración con VS Code
Continue es el asistente de codificación con IA de código abierto líder para VS Code. Se conecta a Ollama y proporciona completado de código en línea, chat y explicación de código directamente en tu editor.
Instala la extensión Continue desde el marketplace de VS Code.
Abre el archivo de configuración de Continue (~/.continue/config.json)
Añade Ollama como proveedor:
{
"models": [
{
"title": "Llama 3.1 8B",
"provider": "ollama",
"model": "llama3.1:8b"
},
{
"title": "Codestral 22B",
"provider": "ollama",
"model": "codestral:22b"
}
],
"tabAutocompleteModel": {
"title": "Qwen Coder",
"provider": "ollama",
"model": "qwen2.5-coder:7b"
},
"embeddingsProvider": {
"provider": "ollama",
"model": "nomic-embed-text"
}
}Esta configuración te proporciona un panel de chat alimentado por Llama 3.1 para preguntas generales, completado de código con Qwen Coder para sugerencias en línea y embeddings locales para búsqueda en la base de código. Todo funciona localmente sin que los datos salgan de tu equipo.
Agente de codificación con IA integrado en el entorno de desarrollo

Integración con JetBrains
Para IntelliJ, PyCharm y otros IDE de JetBrains, el plugin CodeGPT proporciona funcionalidades similares. Configúralo para que use Ollama como backend estableciendo el extremo de la API en http://localhost:11434 y seleccionando tu modelo preferido.
Flujo de trabajo basado en terminal
Para desarrolladores que trabajan en la terminal, aichat es una excelente herramienta de línea de comandos que proporciona una interfaz de chat, generación de comandos de shell y flujos de trabajo basados en tuberías:
# Instalar aichat
cargo install aichat
# Configurar para usar Ollama
# Editar ~/.aichat/config.yaml
cat > ~/.aichat/config.yaml << 'EOF'
clients:
- type: ollama
server: http://localhost:11434
models:
- name: llama3.1:8b
- name: codestral:22b
EOF
# Usarlo
aichat "Explica esta expresión regular: ^(?=.*[A-Z]).{8,}$"
echo "def fibonacci(n):" | aichat "Completa esta función de Python"Construye tu primera aplicación local de IA
Con tu entorno configurado, vamos a crear una aplicación sencilla que demuestre el flujo de trabajo completo de desarrollo de IA local. Crearemos un script en Python que utiliza Ollama para análisis de texto, un patrón que reutilizarás en innumerables proyectos.
# demo_ia_local.py
import requests
import json
URL_OLLAMA = "http://localhost:11434/api/chat"
def analizar_texto(texto: str, tarea: str) -> str:
"""Envía una solicitud de análisis de texto a un modelo local de Ollama."""
response = requests.post(URL_OLLAMA, json={
"model": "llama3.1:8b",
"messages": [
{"role": "system", "content": f"Eres un asistente de análisis de texto. {tarea}"},
{"role": "user", "content": texto}
],
"stream": False,
"options": {"temperature": 0.2}
})
return response.json()["message"]["content"]
# Ejemplo de uso
articulo = """
La inteligencia artificial está transformando la prestación de
servicios sanitarios a través de diagnósticos mejorados, planes de
tratamiento personalizados y procesos administrativos optimizados.
Sin embargo, las preocupaciones sobre la privacidad de los datos, el
sesgo algorítmico y el desplazamiento de profesionales médicos siguen
siendo significativas.
"""
resumen = analizar_texto(articulo, "Resume los puntos clave en 3 viñetas.")
sentimiento = analizar_texto(articulo, "Analiza el sentimiento e identifica las preocupaciones.")
print("Resumen:", resumen)
print("\nSentimiento:", sentimiento)Este patrón sencillo — enviar un prompt con una instrucción de sistema y contenido de usuario a un modelo local — es la base para prácticamente todas las aplicaciones de IA local. Puedes extenderlo con respuestas en streaming, conversaciones de múltiples turnos, llamadas a herramientas y salidas estructuradas a medida que tus necesidades crezcan.
Comparación detallada de rendimiento: GPU vs CPU
Comprender las diferencias de rendimiento entre la inferencia por GPU y CPU te ayuda a establecer expectativas realistas y a elegir el hardware adecuado para tus necesidades:
| Configuración | Tamaño del modelo | Tokens/segundo | Tiempo hasta el primer token | Caso de uso |
|---|---|---|---|---|
| RTX 4090 | 8B | 80-120 | 0,1 s | Chat interactivo, desarrollo rápido |
| RTX 4090 | 70B (4 bits) | 15-25 | 0,5 s | Razonamiento complejo, revisión de código |
| M3 Max 64 GB | 8B | 50-80 | 0,2 s | Desarrollo, asistencia de codificación |
| M3 Max 64 GB | 70B (4 bits) | 8-15 | 1,0 s | Investigación, generación de texto largo |
| Intel i9 | 8B | 5-10 | 2-5 s | Pruebas, procesamiento por lotes |
| Apple M2 | 8B | 20-40 | 0,3 s | Desarrollo, uso ligero |
Estas cifras son aproximadas y varían según el nivel de cuantización, la longitud del contexto y el tamaño del lote. La conclusión clave es que la aceleración por GPU proporciona una mejora de velocidad de 5 a 20 veces respecto a la inferencia por CPU, lo que la hace esencial para casos de uso interactivos, pero opcional para el procesamiento por lotes, donde la latencia no es una preocupación.
Solución de problemas comunes
El modelo se queda sin memoria: Usa un nivel de cuantización más pequeño (Q4 en lugar de Q8) o cambia a un modelo con menos parámetros. Ollama selecciona automáticamente la mejor cuantización para tu hardware, pero puedes anularla especificando la etiqueta (por ejemplo, llama3.1:8b-q4_0).
Primera respuesta lenta: La primera solicitud a un modelo después de cargarlo siempre es más lenta porque los pesos del modelo deben cargarse en la memoria de la GPU. Las solicitudes posteriores son mucho más rápidas. Mantén los modelos de uso frecuente cargados ejecutándolos en una sesión persistente.
Ollama no detecta la GPU: Asegúrate de tener instalados los controladores de GPU más recientes. En Linux, es posible que necesites instalar el NVIDIA Container Toolkit para configuraciones basadas en Docker. En macOS, Ollama utiliza automáticamente la aceleración Metal en Apple Silicon.
Calidad de salida inconsistente: Los modelos locales, especialmente los más pequeños, pueden producir calidad variable. Usa ajustes de temperatura más bajos (0,1-0,3) para tareas factuales y más altos (0,7-1,0) para tareas creativas. Proporciona prompts claros y específicos con ejemplos para mejorar la consistencia.
Puntos clave
- El desarrollo local de IA elimina los costes de API, garantiza la privacidad de los datos y permite el trabajo sin conexión, lo que lo hace esencial para el desarrollo profesional de IA.
- Ollama es el gestor universal de modelos que abstrae la complejidad con detección automática de GPU y una API compatible con OpenAI.
- Empieza con un modelo de 8B como Llama 3.1 para uso general y añade modelos especializados (codificación, embeddings) según sea necesario.
- La integración con IDE a través de Continue, CodeGPT o aichat lleva la IA directamente a tu flujo de trabajo de desarrollo.
- La aceleración por GPU proporciona una mejora de velocidad de 5 a 20 veces respecto a la CPU, lo que la hace esencial para uso interactivo, pero opcional para procesamiento por lotes.
- Los equipos con Apple Silicon y memoria unificada ofrecen un excelente rendimiento de IA local, especialmente las variantes Max y Ultra con 64 GB+ de RAM.
- Mantén los modelos de uso frecuente cargados para tiempos de respuesta instantáneos y usa la cuantización para ajustar modelos más grandes a una VRAM limitada.
Conclusión
Configurar un entorno de desarrollo de IA local es una de las inversiones con mayor retorno que un desarrollador puede hacer en 2026. Con Ollama gestionando los modelos, la integración con IDE llevando la IA a tu flujo de trabajo diario y la calidad cada vez mejor de los modelos de código abierto, ahora tienes acceso a capacidades que eran exclusivas de laboratorios de IA bien financiados hace solo dos años.
Empieza con lo básico: instala Ollama, descarga Llama 3.1 e intégralo en tu IDE. A medida que tus necesidades crezcan, añade modelos especializados, experimenta con diferentes niveles de cuantización y construye aplicaciones que aprovechen la API local. El ecosistema de IA local está evolucionando rápidamente, y el entorno que configures hoy solo se volverá más potente a medida que se publiquen nuevos modelos y herramientas. Nunca ha habido un mejor momento para desarrollar aplicaciones de IA, y no hay mejor lugar para hacerlo que en tu propio equipo.
Preguntas frecuentes
¿Puedo ejecutar modelos de IA localmente sin una GPU?
Sí, usando inferencia por CPU a través de Ollama o llama.cpp. Espera entre 5-10 tokens por segundo para modelos de 7B en CPU modernas. Funciona para pruebas y procesamiento por lotes, pero es demasiado lento para chat interactivo. Considera modelos más pequeños (3B o menos) para un mejor rendimiento en CPU.
¿Cuánta RAM necesito para el desarrollo local de IA?
Para modelos de 7-8B con cuantización, 16 GB de RAM del sistema son suficientes. Para modelos de 13B, necesitas 32 GB. Para modelos de 70B, necesitas 64 GB+ o una GPU dedicada con 24 GB+ de VRAM. Los equipos con Apple Silicon pueden usar memoria unificada, por lo que los Mac con chips M-series y 32 GB+ son excelentes plataformas.
¿Es Ollama gratuito?
Sí, Ollama es completamente gratuito y de código abierto bajo la licencia MIT. Los modelos de IA que ejecuta también son gratuitos: Llama 3.1 permite uso comercial, Mistral usa Apache 2.0 y la mayoría de los otros modelos populares tienen licencias permisivas.
¿Cómo mantengo mis modelos locales actualizados?
Ejecuta ollama pull nombre-del-modelo para descargar la última versión de cualquier modelo. Ollama verifica las actualizaciones y descarga solo las capas cambiadas. También puedes ejecutar ollama list para ver los modelos instalados y ollama rm nombre-del-modelo para eliminar versiones antiguas.